 Instituto de Astrofísica de Andalucía
Instituto de Astrofísica de AndalucíaTechnological Developments
Calibration of LOFAR data in the cloud
AMIGA group has collaborated with the University of Edinburgh and the Barcelona Supercomputing center to port a pipeline for calibrating data from LOFAR to different distributed computing infrastructures.
In Sabater et al. (2017), we presented the results of the tests that we performed on different computing resources, in order to evaluate which of them best fulfils the requirements from a new strategy for calibrating LOFAR data. Some preliminary results were published in the poster EGI Federated Cloud for calibrating and analysing Radio‐Astronomy data
LOFAR is currently completely operational and generating high quality data, whose correlation and pre-processing is performed routinely by the observatory. However, the calibration of the data by the final user still presents many challenges:
- Specialized Software. The calibration of the data requires dedicated LOFAR software and its installation and maintenance is especially difficult in old systems.
- High requirements on computing and storage resources. The final data set for a single observation run can amount up to several TB and a simple calibration run could take several CPU-years. However, the pipeline design allows the processing of different chunks of data (see Sect. 2.1) as independent jobs, which individually do not require a high amount of memory or processors.
- Varying hardware requerements. The varying beam that the LOFAR stations produce and the effects of the ionosphere, which are specially strong at low frequencies, pose a challenge to develop efficient calibration pipelines. Indeed, they are still evolving and their hardware requirements change as they are developed or improved.
We performed some tests in three different computing resources: dedicated clusters (the IAA-CSIC and RAL clusters ), grid (IBERGRID) and cloud (EGI Federated cloud, RAL cloud, Amazon Web Services). The difficulty to install and keep updated the required software on both clusters and grid together with the flexibility that a cloud system offers, led us to consider a cloud system as the most suitable platform for our use case.
Therefore we focused on study cloud systems, and we tested three different types:
a) an academic private multi-site cloud system, the European Grid Infrastructure (EGI) Federated Cloud;
b) an academic private one-site cloud managed by the Rutherford Appleton Laboratory (RAL); and,
c) a commercial multi-purpose public multi-site cloud, the Amazon Web Services (AWS) infrastructure. Most of the AWS tests shown in this work were carried within the context of a project titled “Calibration of LOFAR ELAIS-N1 data in the Amazon cloud“, which was granted in the AstroCompute in the Cloud call by Amazon Web Services and the SKA Office.
We performed several tests to assess the suitability and performance of the cloud platforms used to solve our problem. We checked the following points:
- Easy of installing and managing the required software in the infrastructure
- Suitability of the platform
- Data transfer
- Processing performance
- Cost
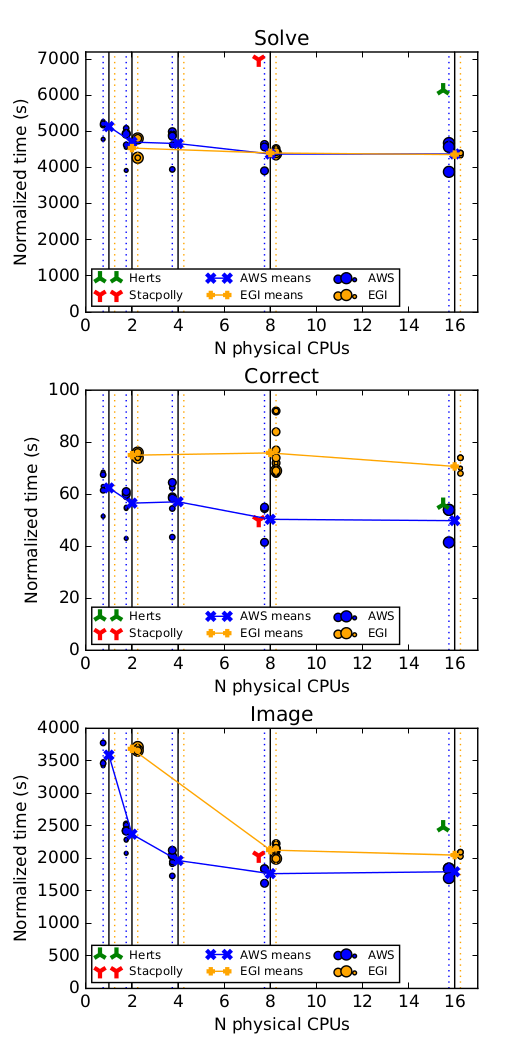
About processing performance
Concerning the processing performance, in the figure 3 of the paper (see below), we show the time taken in the “solve”, “correct” and “image” steps of the pipeline. Given that the CPUs of the AWS instances made use of the Intel Hyper-threading technology, what means that their perfornmance is roughly half of the performance of a physical CPU, we need to normalized, dividing by 2, the number of CPU cores and the time to complete the steps.
Conclusions
As conclusions, we found that good support, documentation, and simplicity of usage were of great importance for the implementation of the pipelines: the requirement of manual intervention had a strong negative impact on the time spent in some infrastructures. On the technical side, processing speed was comparable in the different cloud infrastructures for similar resources. The quantity of memory had little impact on the processing speed once a minimum amount of required memory was available.
The speed of data transfer was not one of the main limiting factors as the transfer time was lower than the computing time.
Finally, we could not find a strong data I/O overhead coming from the use of non-local storage in the clouds. However, we identified a couple of unforeseen issues that
had a negative impact on the implementation of pipelines. The combination of hyperthreading and tasks of the pipelines that are not, or cannot be, fully parallelized produced an empirical overhead in the running time of the pipelines. Additionally, the lack of scratch storage areas of an appropriate size could block the implementation of the pipelines in some systems. Cloud infrastructures presented several highlights, most notably: a) the straightforward and simple installation and maintenance of the software; b) the availability of standard APIs and tools widely used in the industry; c) the flexibility to adapt the infrastructure to the needs of the problem and, d) the on-demand consumption of shared resources.
We found that the run of data calibration pipelines is not just possible but efficient in cloud infrastructures. From the point of view of the final user it simplified many important steps and solved issues that blocked the implementation or running of the pipelines in other infrastructures. In terms of costs, a commercial cloud infrastructure like AWS is currently worthwhile in several common use cases, where the user lacks access to powerful storage and computing resources or specialised support, or where the calibration of small to medium sets of data is needed.